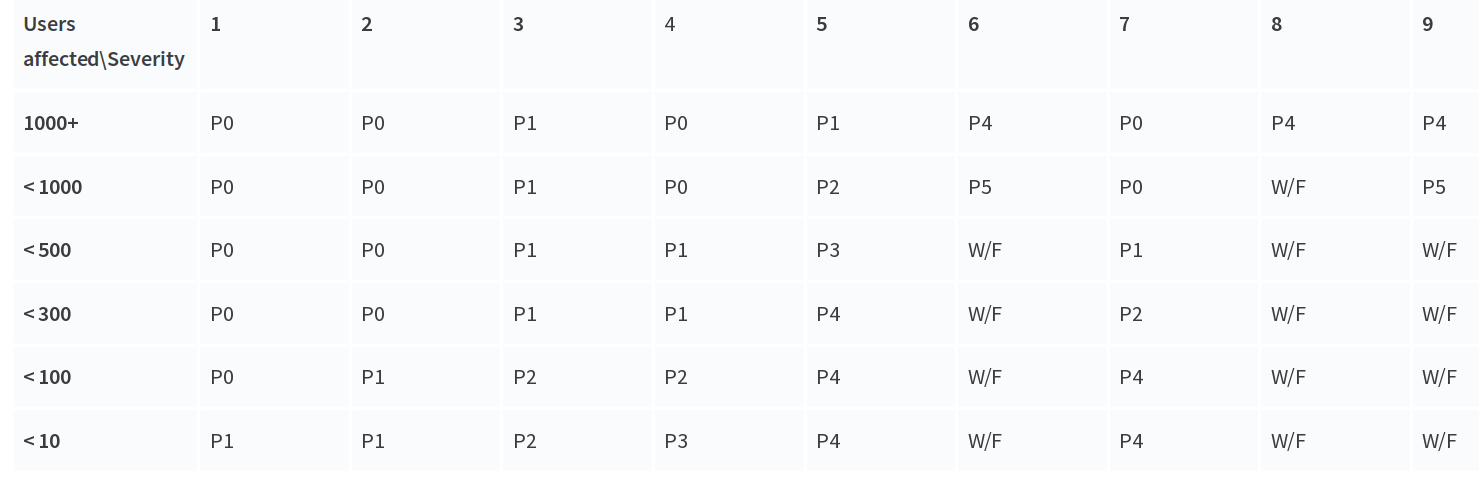
Утечки. XCode Leaks & Allocations. Осторожно XML
 Я люблю сложные задачи, но терпеть не могу, когда не ясно откуда идет проблема, как с ней бороться и куда вообще копать. Третий день бьюсь над проблемами с памятью: после загрузки и выгрузки игровой сцены есть большая утечка порядка 20Мб, что, мягко говоря, много. Изначально я пробовал пользоваться инструментом Leaks, но он не показывал практически ничего. Тогда я обратил свое внимание на инструмент Allocations. Разобраться в том как с ним работать в моем случае было довольно большой головной болью.
Я люблю сложные задачи, но терпеть не могу, когда не ясно откуда идет проблема, как с ней бороться и куда вообще копать. Третий день бьюсь над проблемами с памятью: после загрузки и выгрузки игровой сцены есть большая утечка порядка 20Мб, что, мягко говоря, много. Изначально я пробовал пользоваться инструментом Leaks, но он не показывал практически ничего. Тогда я обратил свое внимание на инструмент Allocations. Разобраться в том как с ним работать в моем случае было довольно большой головной болью.
Итак принцип по которому я работал был следующим:
- Загружаю главный экран. Делаю снимок.
- Загружаю игровой экран, загружаю главный экран, делаю снимок.
- Повторяю пункт 2 еще несколько раз.
- Открываю один из средних снимков и смотрю из-за каких объектов выросла куча
- Устраняю те проблемы, причина которых стала очевидной
- Повторяю все с пункта 1 до тех пор, пока результат работы приложения меня не устроит
А теперь в кратце о неожиданных результатах, с которыми я столкнулся.
XML очень дорогой формат
Итак, я начну с минусов:
- Слишком большие файлы - много избыточной информации
- Довольно долгий парсинг
- Требует довольно большого объема памяти
Плюсы:
- Удобочитаемость - важно особенно на этапе активной разработки, когда нужно что то поменять на лету
- Можно сжать в архив
Большие файлы для меня проблема, так как максимальный размер бандла ограничен, а xml файлов у меня много. Скорость парсинга, конечно, зависит от библиотеки для работы с xml, но, конечно, она несравнима, например, с обработкой бинарного формата. А вот проблема с памятью для меня оказалась большой неожиданностью. Я работаю c xml при помощи tinyxml. Ранее ресурсы были организованы таким образом, что хранился распарсенный xml, и, каждый раз применяя ресурс, я проходил по дереву для получения нужных мне параметров. Здесь открылись две проблемы: один XMLElement в памяти занимал 4Кб, а теперь, если представить сколько этих элементов в среднего размера xml’ке, то можно понять, что это катастрофично. Первым делом я перделал логику таким образом, чтобы парсить xml только при загрузке ресурса, а затем создавать объекты из заранее заполненных структур данных. Это не только освободило изрядный кусок памяти, но и дало большой прирост в производительности. Как показала практика, поиск по элементам в xml намного медленнее, чем, скажем, поиск по unordered_map’у. В итоге, избавившись от постоянной работы с xml, я только выиграл. Следующим шагом, я думаю, стоит перейти с xml на бинарный формат.